
Webfunny可以支持千万级别PV的日活量了。
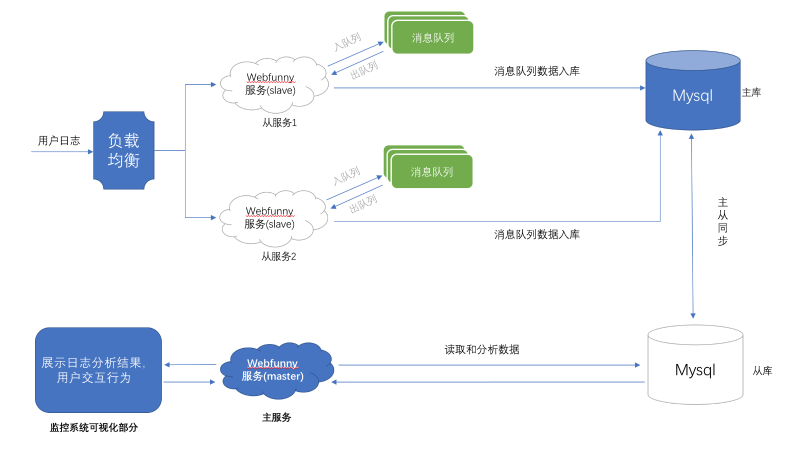
但是,我们默认的部署配置,是无法支持这么高的日活量的,需要我们做一些支持高并发的配置和操作,下面让我们一起看下如何让webfunny支持更高的并发量吧,下图为webfunny高并发架构图:
一、提升mysql最大连接数
正常情况下,如果我们的日志并发量比较高,我们遇到的第一个并发问题,应该是数据库的最大连接数。
如果给mysql设置一个合理的最大连接数,应该就能够支持一定量的并发了。
1. 如何设置mysql连接数,请参考我的这篇博客:Mysql连接数设置
2. 如何设置连接池数量,默认设置500,如果并发量高的用户,可以提高连接池数量,配置文件: config/db_local.js
pool: {
max: 500, // 此处可提升
min: 0,
acquire: 30000,
idle: 10000
}, 二、多点部署
如果你们日活量达到百万、甚至千万的级别,并且你们只部署了一台机器,那么将会遇到另一个瓶颈,就是服务器的TCP连接数不够用了。一旦出现流量高峰,很多日志上报请求都会连接超时,将会丢失大量的日志数据。
此时需要部署多台服务器,来缓解TCP连接数的压力。但是多台服务器的ip不同,如果才能让上报日志分发到不同的服务器上呢?
方式一(推荐):使用阿里云的负载均衡(SLB),将你的上报域名平均分配到多台机器上,即可实现多点部署。
方式二(自己配置):使用Nginx配置负载均衡,又Nginx来分发这些日志上报请求,配置如下:
http {
# 分发
upstream myApps {
server 111.222.96.101:8011 weight=1; # weight 是权重,代表分发的比例
server 111.222.96.102:8011 weight=1; # weight 是权重,代表分发的比例
}
# 代理
server {
location /server/upLog {
proxy_pass http://myApps/server/upLog;
proxy_connect_timeout 3000;
proxy_send_timeout 3000;
proxy_set_header Host $http_host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
}
}
}注意:既然是多点部署,那么就需要区分主从服务器。
1. 选一台服务器作为主服务器,启动方式为:npm run prd;重启命令为:npm run restart
2. 剩下的服务器全都作为从服务器,启动方式为:npm run slave;重启命令为:npm run reslave;从服务器不会执行查询操作。
三、搭建消息队列
使用消息队列(RabbitMq),主要是为了缓解流量高峰的压力,削峰填谷。目前只能够支持RabbitMq,后续将会暴露出消息接口,以支持多种消息队列。
首先、我们需要多个消息队列服务,一台服务器对应一个消息队列。
你也可以安装在当前服务器上 Rabbitmq安装方法如下:
1)ubantu16 安装RabbitMQ服务软件包,很多教程都要求安装erlang, 但是更新apt以后,直接执行安装命令,会自动安装erlang的核心组件的。(erlang始终无法成功安装,真心累。)
$ apt-get update $ apt-get install rabbitmq-server // 安装
$ rabbitmq-plugins enable rabbitmq_management // 启动插件,浏览器才能访问
正常情况下是直接成功的,直接访问ip端口号就可以打开了 http://IP:15672, 如下图:
2)现在我们需要一个有效的登录名和密码,执行如下命令
|
1
2
3
|
$ rabbitmqctl add_user username password // 设置用户名密码$ rabbitmqctl set_user_tags username administrator // 设置为管理员身份$ rabbitmqctl set_permissions -p / username ".*" ".*" ".*" //为用户设置读写等权限 |
OK, 现在我们登录进来就是这样的界面,如此消息队列服务我们算是搭建完成了。
其次、进入monitor/config_variable/config.json文件中,调整参数:messageQueue: true, 进入lib/RabbitMq.js文件中配置消息队列的连接 amqp.createConnection({url: "amqp://用户名:密码@127.0.0.1:5672"});
注意:不可以多台服务器都向同一个消息队列服务添加消息,这样消息队列本身也扛不住。
四、配置读写分离(mysql主从同步)
我们把消息队列服务搭建好以后,就会遇到第二个瓶颈:大数据的查询
因为我们的分析日志的,所以免不了对大数据的分析和查询,如果在进行大量数据查询的时候,遇到了流量高峰,那么数据库的连接数就会瞬间耗尽,从而产生了大量的连接数报警,所以,我需要做读写分离。
1. 我们需要配置mysql的主从同步,有条件的可以配置一主多从。(一般一主一从也就差不多够用了)配置方法请参考:主从同步配置
PS:主从同步的配置比较麻烦,请用户自己查询相关文档,完成配置,或者直接使用运行商的数据库。
2. 配置mysql的最大连接数,mysql默认最大连接数很小,至少是设置1000以上(这个我也说不清设置多少最好,一般设置几千应该没问题)
3. 进入webfunny_monitor/bin/mysqlConfig.js文件中,找到参数「read」,配置从库的连接即可。
好了,到此,我们的webfunny前端监控的高并发配置就算完成了,快去试试吧。
